Empowering Indian Languages: IIT-Madras’ AI4Bharat Unveils IndicVoices, Offering Access to 7,300 Hours of Speech Datasets
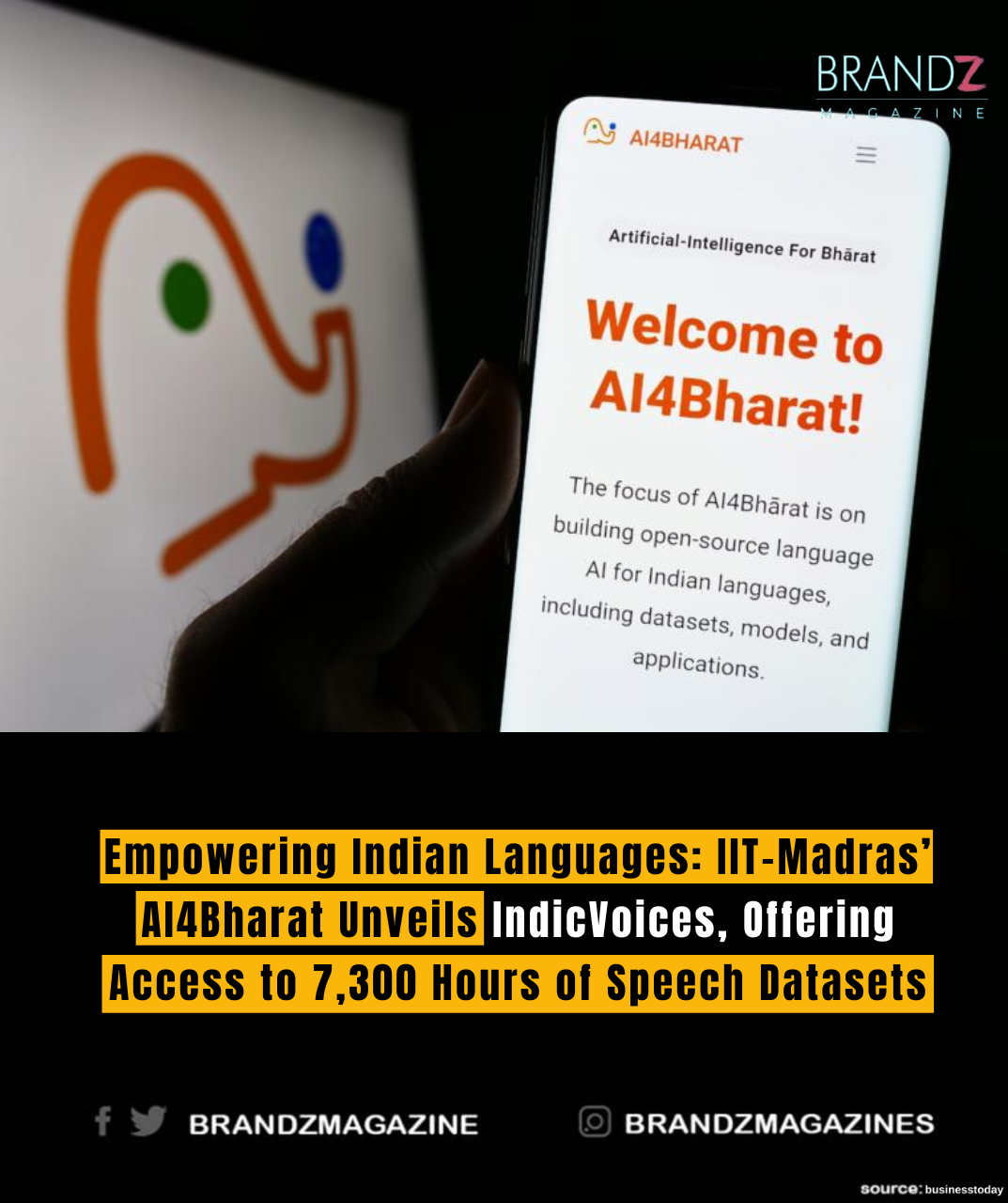
In a significant stride towards bolstering the accessibility and development of Indian language technologies, the Indian Institute of Technology Madras (IIT-Madras) has unveiled “IndicVoices” through its initiative AI4Bharat. This groundbreaking platform offers access to an extensive repository of speech datasets spanning 7,300 hours, aimed at catalyzing advancements in speech recognition and natural language processing (NLP) for Indian languages.
The launch of IndicVoices marks a pivotal moment in India’s technological landscape, addressing a longstanding gap in resources and infrastructure for the development of Indian language technologies. With over 19,000 speakers and 450 dialects represented, the dataset encompasses a diverse range of languages, including Hindi, Tamil, Telugu, Bengali, Marathi, Kannada, Malayalam, Gujarati, Punjabi, and more.
The initiative underscores IIT-Madras’ commitment to fostering innovation and inclusivity in the digital sphere, particularly in the context of linguistic diversity prevalent across India. By providing researchers, developers, and technologists with access to high-quality speech data in multiple Indian languages, IndicVoices aims to accelerate the development of speech recognition systems tailored to the needs of Indian users.
The significance of this initiative extends beyond technological advancements, as it holds the potential to democratize access to digital services and information for millions of non-English speakers in India. With the proliferation of voice-enabled technologies and digital assistants, the availability of robust speech datasets in Indian languages is paramount for ensuring inclusivity and accessibility in the digital realm.
Moreover, IndicVoices is poised to fuel innovation in various domains, including healthcare, education, agriculture, finance, and governance, by facilitating the creation of localized solutions and applications that cater to diverse linguistic communities across India. From voice-based virtual assistants to speech-to-text transcription services, the possibilities for leveraging Indian language technologies are vast and far-reaching.
The launch of IndicVoices also reflects the growing recognition of India’s potential as a global leader in artificial intelligence and machine learning, particularly in the domain of natural language processing. With the concerted efforts of academia, industry, and government bodies, initiatives like AI4Bharat are playing a pivotal role in harnessing India’s rich linguistic heritage to drive innovation and societal impact.
However, the journey towards advancing Indian language technologies is not without its challenges. Despite the rapid strides made in recent years, there is still a pressing need for continued investment in research, infrastructure, and talent development to realize the full potential of Indian language technologies. Additionally, addressing issues related to dialectal variations, low-resource languages, and domain-specific vocabulary poses ongoing challenges that require collaborative efforts from stakeholders across sectors.
In conclusion, the unveiling of IndicVoices by IIT-Madras’ AI4Bharat initiative marks a significant milestone in India’s quest to empower its linguistic diversity through technology. By providing access to a vast repository of speech datasets, IndicVoices holds the promise of driving innovation, fostering inclusivity, and unlocking new opportunities for digital transformation across diverse linguistic communities in India. As we look towards the future, initiatives like IndicVoices serve as beacons of progress, paving the way for a more inclusive, accessible, and technologically empowered India.


